email-design.md: how we made AI emails actually on-brand
AI agents read CLAUDE.md and llms.txt. So why does your brand still live in a database? How we replaced our structured brand object with a dynamic email-design.md — and why a document beats a schema when the reader is an LLM.
Your coding agent reads a CLAUDE.md before it touches a line of your code. Your docs site probably ships an llms.txt so models can find their way around. Half the repositories I cloned this year had an AGENTS.md sitting in the root, quietly briefing whatever agent showed up on how the project actually works.
So here's the question that nagged at me for months: if every serious AI system now gets handed a markdown file before it does anything, why was the most important context we had — a customer's brand — still trapped in a database?
This is the story of how we stopped storing brands as objects and started writing them as documents. We call the format email-design.md, and it's the single biggest reason Brew's emails actually look on-brand now.
Markdown quietly became the language AI speaks
I didn't notice this trend happening until it had already happened.
In August 2025, OpenAI, Google, Cursor, and a handful of others agreed on AGENTS.md — one markdown file at the root of your repo that tells any coding agent how to build, test, and not break your project. It's now stewarded by the Linux Foundation and lives in north of 60,000 repositories. A year before that, Jeremy Howard proposed llms.txt: a markdown index that points a model at the parts of your site worth reading. Stripe ships one. Anthropic ships one. Cursor ships one — six hundred sites and counting. And Claude Code, the tool half my team lives in, reads a CLAUDE.md before every single task.
Different files, same instinct. When you want to brief an AI, you hand it a markdown document.
There are good reasons it shook out this way, and they're worth saying out loud because they're exactly the reasons it works for brand too. Models were trained on a web that is overwhelmingly markdown — every README, every Stack Overflow answer, every doc page. It's their native dialect. The headings give a model hierarchy for free: this is the main idea, this is a sub-point, this is a list of rules. It's readable by a human and parseable by a machine at the same time, so there's exactly one source of truth instead of a document and its database shadow. It's dense — fewer tokens than the equivalent JSON. And it never blows up on a missing bracket. A half-truncated markdown file is still useful; a half-truncated JSON object is garbage.
Anthropic has a good phrase for the discipline of deciding what an agent should actually see — context engineering. Once you start thinking that way, the format of your context stops being an implementation detail and becomes the whole game.
We learned that the hard way.
How we used to capture a brand: the brand object
When we started Brew, we did the obvious engineer thing. A brand is structured data, right? So we modeled it.
We had a table — call it the brand object. Dozens of design tokens for color and type, a tree of assets and links, and a sprawling style profile with — I am not exaggerating — well over a hundred fields, one for every visual dimension we could think of: palette, lighting direction, even camera angle, each decomposed into a named property with a type. Something would crawl a website, fill in the boxes, and then at generation time we'd read the boxes back out and reassemble them into something the model could use.
On paper it was beautiful. Typed. Validated. Predictable. Every field had a home.
In practice, the emails came out fine. The right blue. The right font. AA contrast, every time. And completely generic — a template with the brand's colors swapped in. They were technically on-brand and recognizably no one's.
It took us embarrassingly long to understand why, and the answer is simple once you see it. A hex code tells you a brand uses #2E5BBA. It does not tell you that the brand puts a tiny mono eyebrow label above every headline, that it draws its dividers as 1px hairlines and never as boxes, that it writes its CTAs like terminal commands. That second category — the signature moves — is the entire reason an email looks like it belongs to somebody. And there was no field for it. There was never going to be a field for it, because the next brand's signature move would be something we hadn't thought to add a column for.
The schema captured what a brand looked like. It had no way to hold why. And anything it couldn't hold, it quietly threw away.
And it went deeper than any one brand. To have a field, you need a strict definition for it — and then every brand you onboard, across every industry, size, and company type, has to fit that same set of fields. A law firm, a streetwear label, a Series B fintech, a neighborhood bakery, all squeezed into one rigid shape. But brands aren't shaped like a schema. They're fluid, a little contradictory, and gloriously specific. Forcing each one into identical boxes was fitting a round peg into a square hole — and the parts that wouldn't fit, usually the exact parts that made the brand that brand, got shaved off until they did.
It got worse from there. Every new idea meant a migration. The nested JSON we shipped into the model's context was enormous and mostly noise — we were spending the agent's attention on field names and braces for a job that is fundamentally about taste and prose. We had built a very precise way to describe a brand that lost the brand in the process.
What if the brand spec was just a document?
The unlock, when it came, was almost too obvious.
When you hire a senior brand designer, they don't hand you a JSON blob. They hand you a brand guide. A document — prose, with exact values where exact values matter, and the reasoning sitting in between. The hex codes are in there, but so is the intent: use the accent sparingly, let the photography breathe, never center the logo.
So recently we stopped asking our extraction agent to fill in fields. We asked it to write the guide.
We rebuilt brand extraction from scratch. Now an agent researches a brand the way a person would — reads the site, studies the screenshots, looks at the real emails — and then it does what a designer does at the end of all that research. It writes it down. The output isn't a row in a table. It's a document called email-design.md.
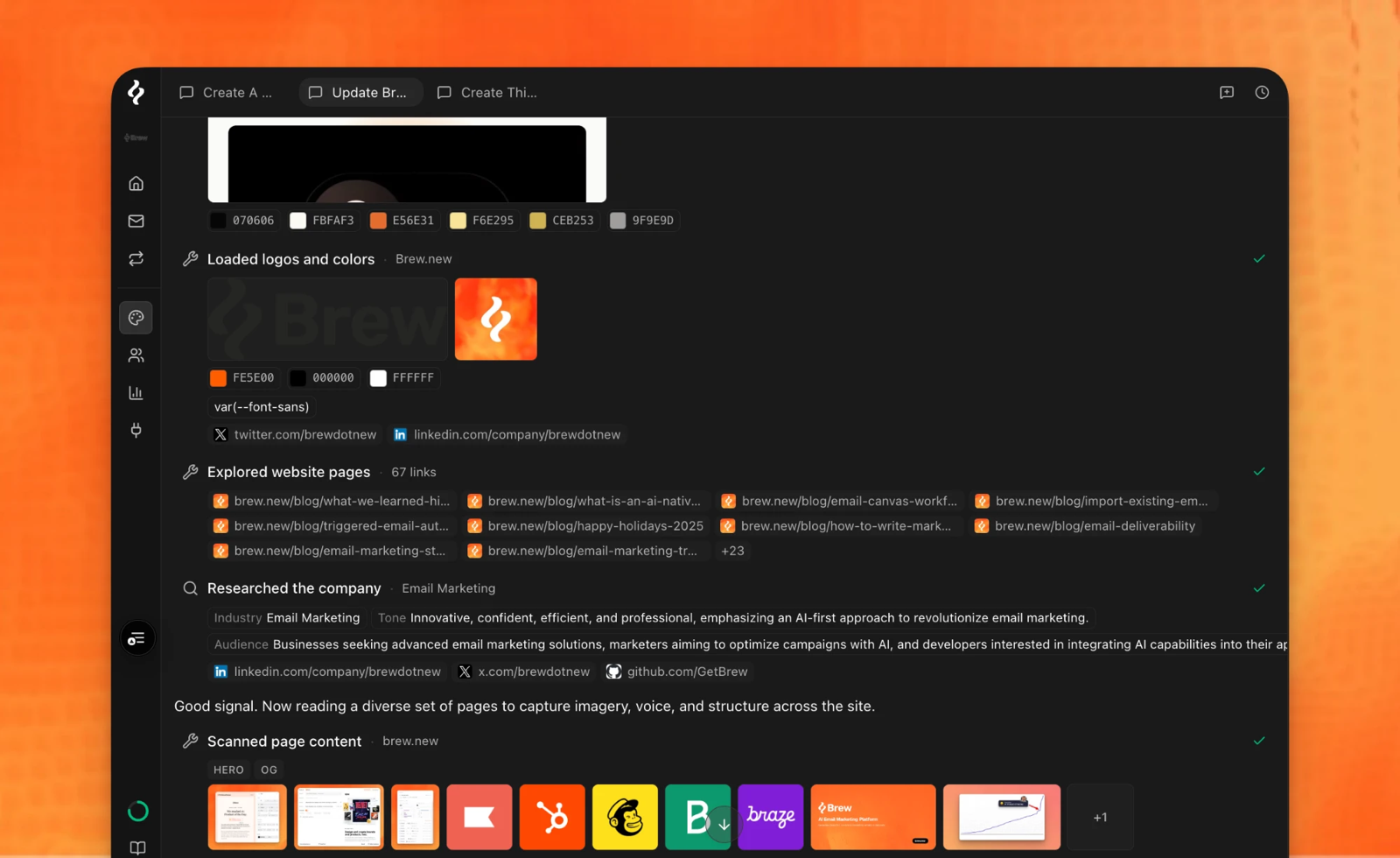
The extraction agent doing its homework — logos, colors, links, company research, and a sweep of real pages — before it writes a single line.
What email-design.md actually is
It's exactly what it sounds like: a markdown file that describes how this one brand does email. Here's a trimmed version of what the agent writes:
# Acme — Email Design
## Brand Essence
Acme is for engineers who are tired of marketing fluff. The emails read
like good documentation: direct, confident, a little dry.
## Signature Moves
- A mono eyebrow label in the accent color above every headline
- Hairline dividers — never boxes, never drop shadows
- Pill CTA, medium weight, no uppercase
- One product screenshot per email, full-bleed, no frame
# ...color system, typography, layout, voice, and component recipes follow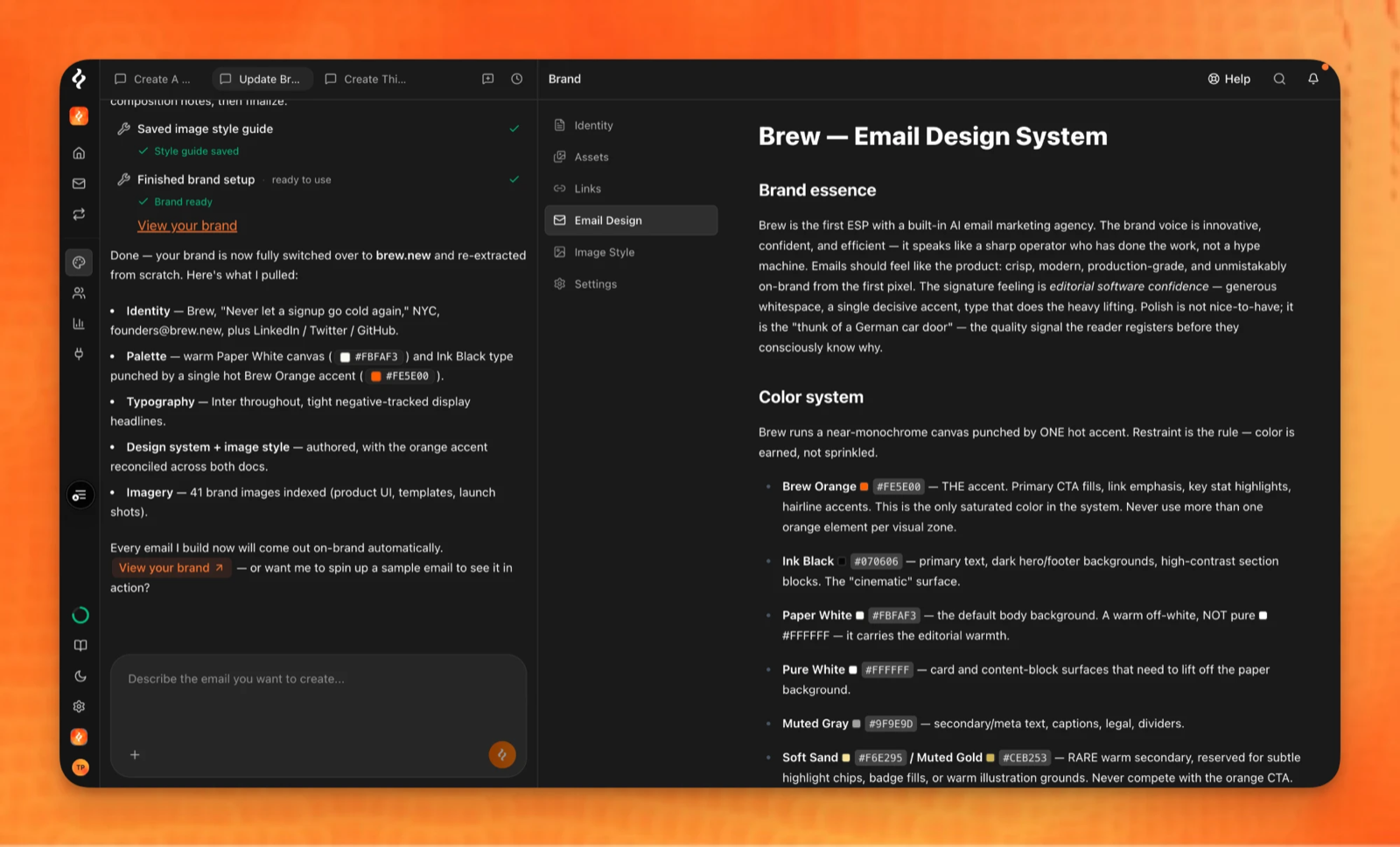
The same kind of file, rendered in Brew — in fact, Brew's own. The agent wrote it from the site; edit any line and the next email follows.
Three things matter about this file, and all three are things the old object couldn't do.
It's agent-written. The extraction agent authors it from research, the same way a designer would write up a brand after a discovery call. You don't fill out a form.
It's human-editable. It's just markdown. If the agent gets your voice slightly wrong, you open the file and fix the line. You don't file a ticket to add a database column — you edit a sentence.
And it's the source of truth. When Brew generates an email, this document goes into the agent's context as the thing to follow — exact hex values, exact fallback font stacks, the signature moves, the voice. Not a reconstruction assembled from tokens. The actual document, read the way it was written.
And it's email-safe by construction. Everything written into it is something that actually survives the inbox — which, as anyone who has shipped an email knows, is a far shorter list than what works on the web.
Which gets at the thing I most want you to take from this. The format is the easy part — it's just markdown; you could sketch one on a napkin. The hard part, the part that took us a year, is reading a brand well enough to name its signature moves, then turning them into email that renders right in every inbox on earth. The document is just where that work lands. Doing the work is the whole job — and it's what Brew is.
Why email-design.md, not design.md
You might be wondering why it's email-design.md and not just design.md. Fair question — and the answer is most of the reason this works at all.
A brand's design system and a brand's email design system overlap, but they are not the same thing, and the gap between them is exactly where generic AI emails go to die.
Email is a hostile medium. It's arguably the worst rendering target in modern software. Your email doesn't run in a browser; it runs in a few dozen of them at once — Gmail, Apple Mail, Outlook (still rendering with Word's engine in places), Yahoo, Superhuman, the native mobile clients — each in light mode and dark mode, each with its own bugs. No flexbox. No grid. Web fonts that may never load. Layouts built out of nested tables like it's 2005. Styles inlined because <style> blocks get stripped. A button isn't a <button> — it's a bulletproof table cell. And dark mode will cheerfully invert the colors you spent all that effort choosing unless you explicitly tell it how to behave.
A generic design system — your website tokens, your Figma library, your print brand book — knows none of this. Drop it into an email generator and you get something gorgeous in the preview and broken in Outlook. So email-design.md isn't a brand guide that happens to mention email. It's a brand guide written in the grammar of email: light- and dark-mode palettes, email-safe fallback font stacks, the 600px container, table-based component recipes, the spacing and styling that actually survive the inbox. It captures the brand and the medium in one document, because in email you can't separate them.
That's also why imagery gets its own file in Brew — image-style.md. Different asset, different constraints, different document. A web design.md could absolutely exist one day. We just think every medium earns its own spec, instead of one schema pretending to cover them all.
Start from what you already have
You don't have to start from a blank page — and you don't have to start from your website alone, either.
Most brands we onboard already have something: a brand guide as a PDF, a messy brand.md someone wrote in Notion, a folder of logos and product shots, a slide deck from the design team, a handful of emails they're quietly proud of. That material is gold, and the old schema had nowhere to put most of it. A document does.
So when Brew builds your email-design.md, it works from your domain and from whatever you hand it — together, alongside each other. Drop in your brand guidelines, PDFs, existing markdown, logos, screenshots, product imagery, past emails. The agent reads all of it the way a sharp new designer would on day one: your live site for how you actually show up in the world, your files for the rules you've already written down.
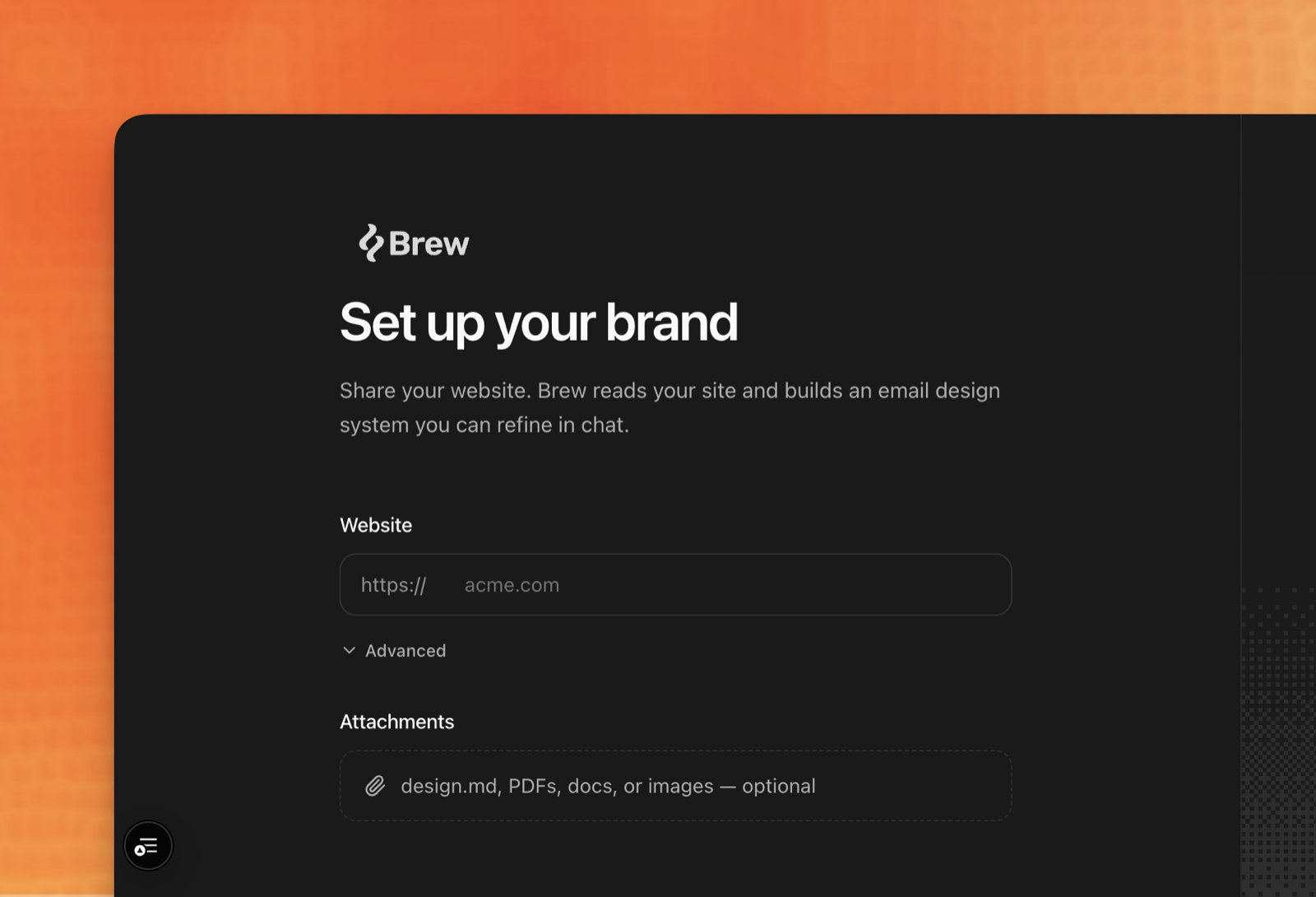
Your domain plus your files. Brew reads both — and on any conflict, your files win.
And when the two disagree, your material wins. We made that a rule: an uploaded brand guide outranks anything inferred from the domain. If your guide says the accent is #FF5A1F and the marketing site drifted to a slightly different orange last quarter, the guide is the source of truth and the site is just a hint. The domain only fills the gaps your uploads leave. You're not correcting the AI after the fact — you're handing it the brief up front.
And if your guidelines already live in markdown, even better: you're handing the agent something already in its native format. But a PDF brand book works just as well. That's the whole point of a document — it can absorb the one you already have.
Why a document beats a schema
| The brand object (old) | email-design.md (new) |
|
|---|---|---|
| Shape | A fixed schema, 100+ fields | A document, written in prose |
| Captures | What a brand looks like | What and why — the signature moves |
| A new idea means | A schema migration | Adding a section |
| To tweak it | File a ticket, change a field | Open the file, change a line |
| Who authors it | A scraping pipeline | An agent — or you |
| The medium | Generic design tokens | Email-native: dark mode, fallbacks, tables |
| Customizing output | Re-roll and hope | Edit one line; every email inherits it |
I want to be careful here, because two things happened at Brew over the past few weeks and it would be easy to take credit for the wrong one. We rebuilt how our email agent thinks about design in general — that's a separate post — and we moved brand context out of the object and into the document. I'm going to try hard to only claim what the document actually earned.
The floor, not the average
We don't grade ourselves on vibes. Every change gets scored against a library of genuinely great real-world emails — the kind that get featured for their craft, not just for being inoffensive. The bar isn't 'is this technically fine,' it's 'could this sit on the front page of the best email galleries.' That lets us see real movement instead of guessing at it.
Here's the honest result. The average score barely moved — and that's the part I trust most, because it means I'm not about to oversell you. What moved was the floor.
The worst emails stopped being broken. Whole classes of defect that used to slip through — hallucinated logo URLs in the header, invented product names, a footer assembled from nothing — disappeared. They disappeared for a boring, satisfying reason: the document says which wordmark to use and what the product is, in prose, so the model never has to make it up. A schema left those as gaps the model would helpfully fill with fiction. The document closes the gap.
The context got leaner
The second win was efficiency. A document is dramatically leaner than the pile of structured data it replaced — on an image-heavy brand, it cut the context the agent has to wade through by roughly two-thirds. Prose compresses where structured data sprawls, and the model spends its attention on the design instead of on field names.
It carries intent, not just values
But the deepest reason a document wins isn't in any chart. It's that markdown can carry intent, and a schema can only carry values. "Spend the accent on one thing per email." "Seamless images that dissolve into the band, or framed images that deliberately contrast — never the half-matched middle." Those are the sentences that separate a designed email from a filled-in template, and there is no column for a sentence. When the agent can read the why, it makes principled choices in the situations you didn't explicitly cover — which is most of them.
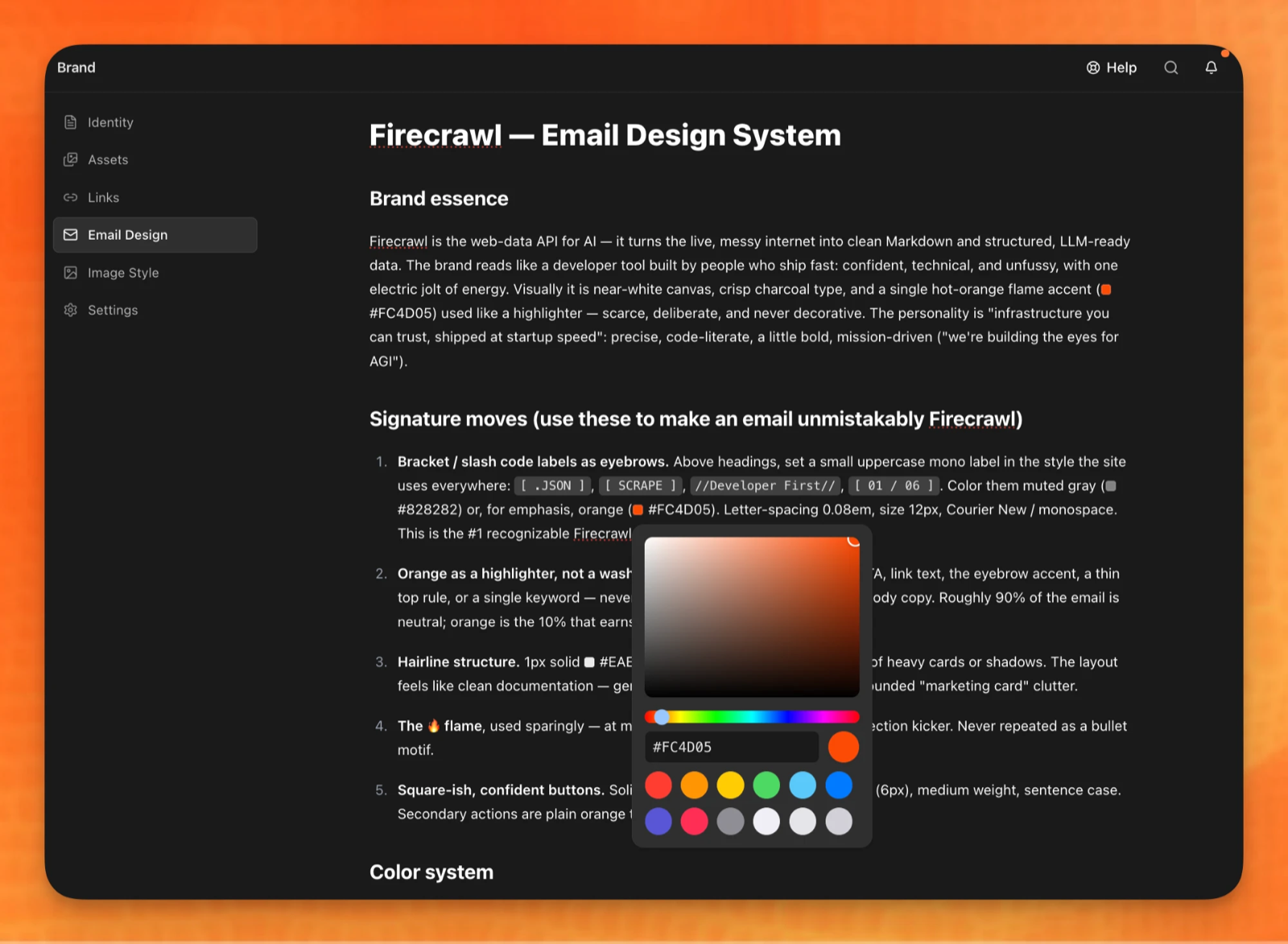
A real one — Firecrawl's email-design.md. Signature moves like bracket eyebrows and a single flame accent, written down as rules an agent can follow instead of a hex code it has to guess around.
On-brand by default, yours to bend
And here's the result customers feel first: the emails come out more on-brand by default, and far easier to change after. When a generation lands 90% of the way there, you don't re-roll the dice and pray. You open the email-design.md, switch pill buttons to square, nudge the accent hue, tighten the voice — and every email from then on inherits the edit. On-brand out of the box, and yours to bend in a single line. The old schema could give you neither at once: rigid where you wanted room, vague where you wanted precision.
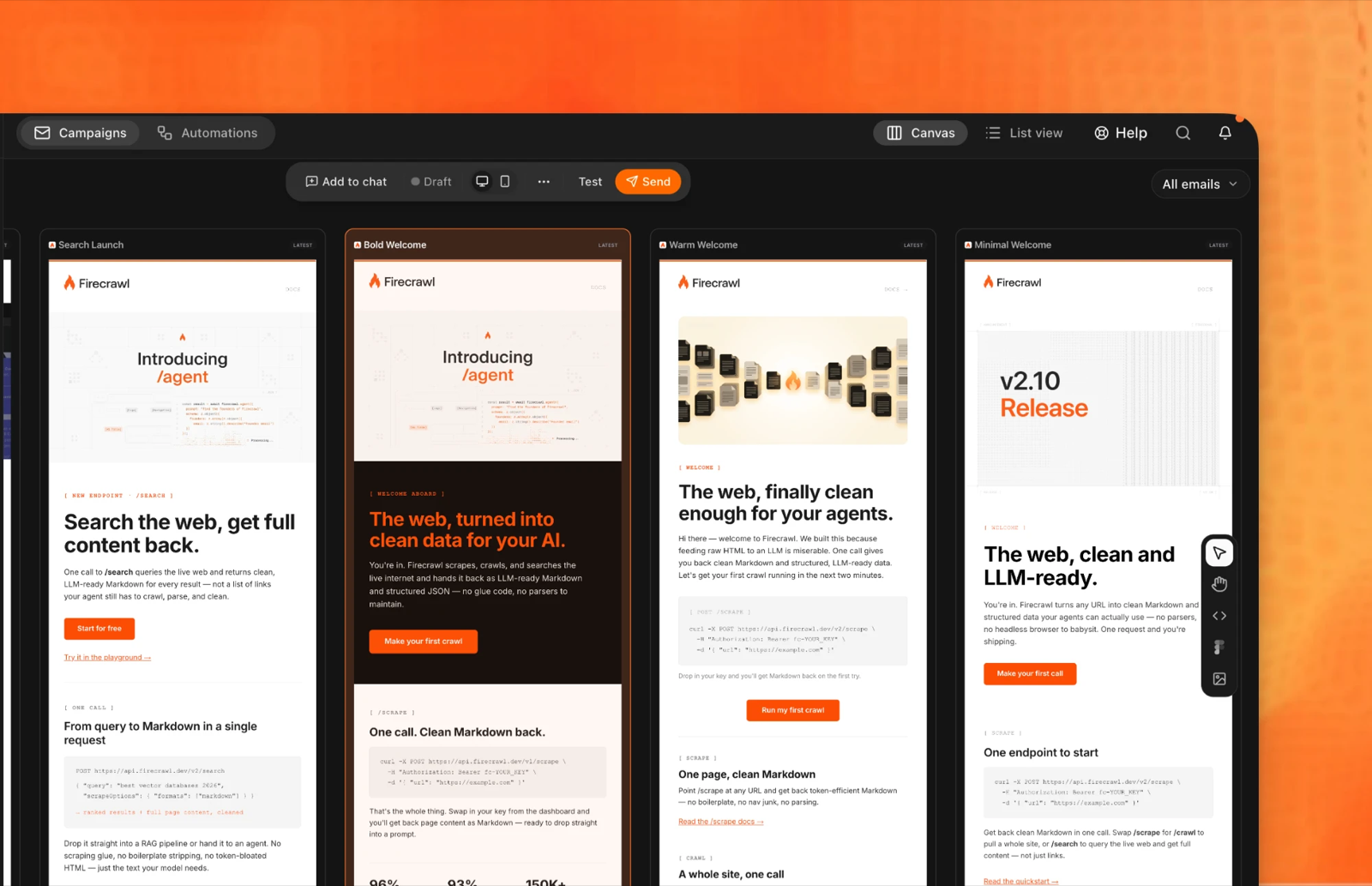
What that spec produces: four Firecrawl campaigns — a launch, two welcomes, a release — each unmistakably the same brand. One email-design.md, many on-brand emails.
email-design.md is the new primitive
Here's the bigger bet, and the reason I wanted to write this down.
AGENTS.md is the README for coding agents. llms.txt is the table of contents for a website. email-design.md is the same kind of object for brand: the brief you hand a generation agent so it knows how to be you. It's the right container for the job because it's everything the brand object wasn't — a human can write it, an agent can write it, an agent can read it, you can version it in git, and you can extend it with a new section instead of a schema migration.
There's a pattern underneath all of these files, and it's the real shift in how software talks to AI: you stop wiring a model into a rigid API and start handing it a document it can read and rewrite. Tools let an agent do things; context like this tells it who to be. The products that feel magical right now get both halves right.
As more of marketing gets handed to agents, every brand will end up with a file like this — the canonical, portable description of how it shows up. We're not waiting around for that future. We're building it.
Coming soon: your brand, in your agent stack
Here's where this gets fun.
If your brand is just a markdown file, there's no reason it should stay locked inside Brew. So the next thing we're shipping is an MCP server.
The Model Context Protocol is the open standard for plugging AI tools into outside systems, and it's a natural fit for something that's already a document. With it, you'll be able to read, iterate on, and operate your brand's email-design.md from wherever you already work — Claude Code, Cursor, your own agents — and call Brew's creative engine to generate finished, on-brand emails from anywhere. Edit a signature move in your editor. Regenerate a campaign from a script. Wire your brand into the same agent pipeline that already runs the rest of your marketing.
That's the whole bet taken to its conclusion, and it's aimed squarely at a role that barely existed three years ago. Call them the AI-native marketer, the GTM engineer, the one-person team doing what used to take a department — they already run paid, lifecycle, content, and outbound with a stack of agents holding the rope. Email was the last channel that still looked like 2018, the one that didn't fit how they work. A brand that lives in markdown and speaks MCP fits anywhere an agent can reach — which, for that operator, is everywhere they already are.
The thunk in the car door
We have a running idea at Brew that polish isn't a nice-to-have, because that phrase implies the user doesn't feel it. Polish is the sound a German car makes when you close the door. The car drives the same without it. But you remember the thunk, and it's part of why you love the car. My co-founder Philip wrote about it after our Product Hunt launch, and a customer there put it better than we ever have: "you did to email what Claude did to design."
For a long time that thunk lived in my head and a hundred fiddly rules I couldn't quite hand to a machine. Now it lives in a markdown file — one per brand, written down, editable, and read out loud every time we generate an email. The taste finally has a home the agent can actually read.
If you've ever watched an AI tool produce something technically on-brand and unmistakably soulless, you already know the gap we were trying to close. Hand us your site, or hand us your brand guide, and we'll write the email-design.md for you — then you can open it up and make it more you.

Ready to send better email?
Brew creates professional, on-brand emails in under 60 seconds.